feat: 076
This commit is contained in:
32
content/post/076.text-recover/index.md
Normal file
32
content/post/076.text-recover/index.md
Normal file
@@ -0,0 +1,32 @@
|
||||
---
|
||||
title: "「小工具」乱码恢复工具"
|
||||
categories: [ "程序人生", "前端技术" ]
|
||||
tags: [ "text", "乱码", "乱码恢复" ]
|
||||
draft: true
|
||||
slug: "text-recover-tool"
|
||||
date: "2024-04-01T13:26:00+0800"
|
||||
---
|
||||
|
||||
## 工具介绍
|
||||
|
||||
在日常工作中,我经常会遇到一些乱码问题,比如文件编码不一致、文件编码错误等。这时候我就需要一个乱码恢复工具来帮助我解决这些问题。自己琢磨了一会儿,写了一个小工具,可以帮助我快速恢复一些字符串乱码。
|
||||
|
||||
引起这个问题的主要原因就是解码目标编码和实际编码不一致,导致乱码。这个工具可以帮助你快速恢复这些乱码问题。
|
||||
|
||||
## 技术栈
|
||||
|
||||
本来想用 Python 来写这个小工具,但是考虑到 Python 的环境配置比较麻烦,所以最后选择了 JavaScript 来实现这个小工具,我的目标是随处可以运行,无需任何环境配置。
|
||||
|
||||
于是就想到了类似于 Electron 之类的跨平台方案,但是一个小工具 100 多 M 的体积实在是太大了,所以最后选择了 Tauri 来打包。
|
||||
|
||||
## 开源地址
|
||||
|
||||
这个小工具已经开源,你可以在 [我的私人 Gitea](https://git.taurusxin.com/taurusxin/text-recover) 上找到它。
|
||||
|
||||
## 使用方法
|
||||
|
||||
使用方法非常简单,只需要将乱码字符串粘贴到输入框中,就可以根据原始编码和目标编码的不同得到恢复后的字符串。
|
||||
|
||||
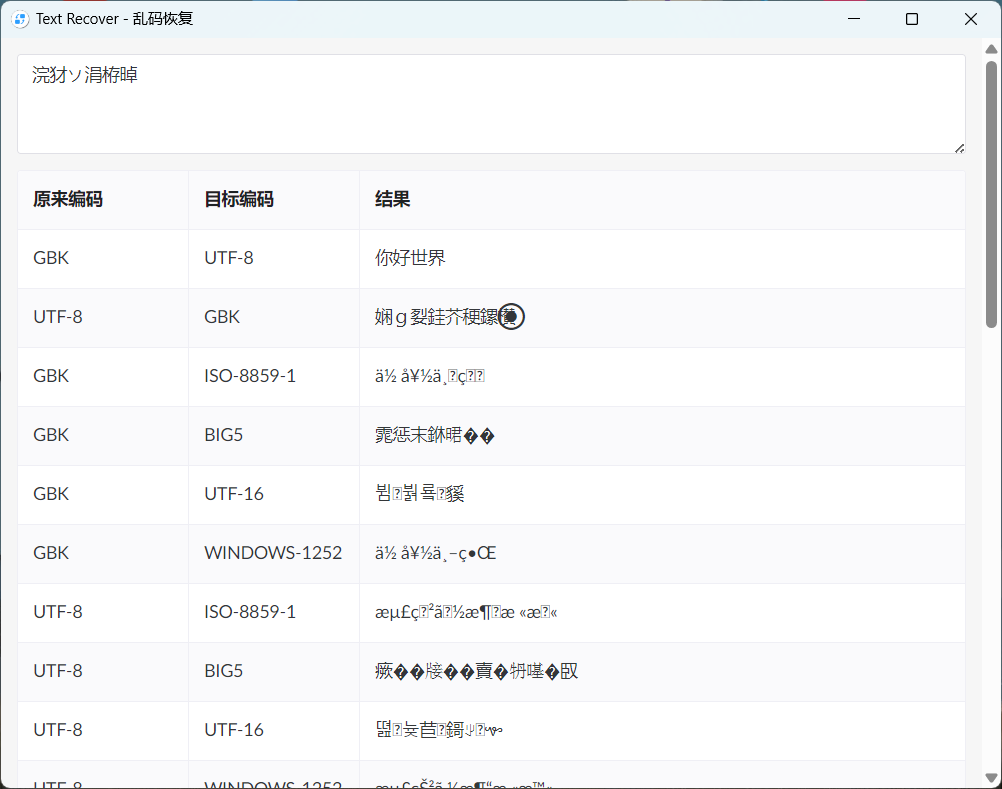
|
||||
|
||||
上图中,字符串被错误编码为GBK,得到“浣犲ソ涓栫晫”,正确使用UTF-8解码为“你好世界”。
|
||||
Reference in New Issue
Block a user