4.1 KiB
title, categories, tags, draft, slug, date
| title | categories | tags | draft | slug | date | |||
|---|---|---|---|---|---|---|---|---|
| 世界上最快的 AI 模型提供商 Cerebras |
|
|
false | cerebras | 2025-11-10T13:51:00+0800 |
前言
好久没更新文章了,关于 AIGC 相关的文章(部署、使用、MCP……),网络上可有太多现有的文章,我就不在这里过多赘述了。
但是最近我注意到了一个新的 AI 模型提供商,让我瞬间眼前一亮。
介绍给各位使用 —— Cerebras
模型对比
在测试 cerebras 前,我们先来看看其他接口模型的 Token 生成速度,我日常会使用到的提供商有:硅基流动、火山引擎包括最近开始使用的的阿里云百炼。
测试环境为:
- Cherry Studio
模型有:
- 硅基流动 - DeepSeek V3.1
- 火山引擎方舟 - DeepSeek V3.1 Termius
- 阿里云百炼国际版 - Qwen3 Max
使用的 prompt 如下,所有模型配置均为默认,没有系统提示词
请注意:该测试仅评估模型输出速率,不评估模型输出内容质量
请你帮我编写一个 React 应用程序,使用 TypeScript 语言,且不使用任何其它库,程序的内容如下
1. 一个 Todo List App,具备基本的功能(添加、删除、标记完成、取消标记等)
2. 支持为未来设定待办事项
3. 支持保存数据到本地,每次打开或刷新浏览器时都能保持数据
结果如下
| 提供商 | 模型 | 首字延迟(ms) | 输入Token数 | 输出 Token 数 | 输出耗时 | 输出速度(Token/s) |
|---|---|---|---|---|---|---|
| 硅基流动 | DeepSeek V3.1 | 727 | 83 | 2306 | 121.3 | 19.01 |
| 火山引擎方舟 | DeepSeek V3.1 Termius | 712 | 81 | 3331 | 95.1 | 35.03 |
| 阿里云百炼国际版 | Qwen3 Max | 1487 | 88 | 2877 | 82.2 | 35 |
基本都是在 50 T/s 以下,当然这仅仅是一个对我我常用的模型接口的随机测试,不能代表所有模型设施的性能。
Cerebras
打开 cerebras 的官网,就能看到大大的一行 “世界最快 AI 基础设施” 的字样,可见他们对自家 API 的对话生成速度非常自信
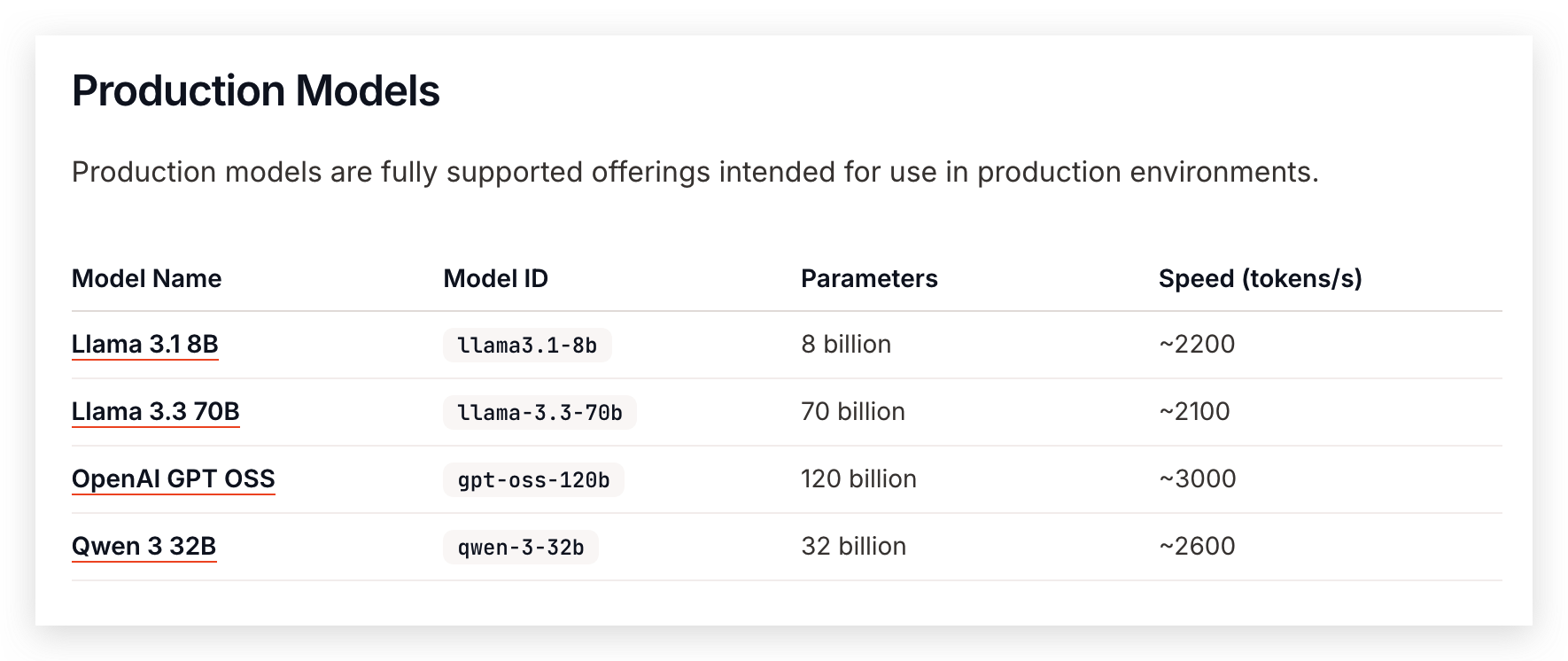
文档中介绍的速度均可达到 2-3 kT/s,非常恐怖,目前支持的模型不多, qwen3-code-480b
最后我们就来实际测试一下 cerebras,注册好账号后,生成一个 key,导入到 Cherry Studio,模型使用最快的 OpenAI GPT OSS,然后要做的,就是点击发送
| 提供商 | 模型 | 首字延迟(ms) | 输入Token数 | 输出 Token 数 | 输出耗时 | 输出速度(Token/s) |
|---|---|---|---|---|---|---|
| Cerebras | GPT OSS | 656 | 183 | 3265 | 1.48 | 2197.17 |
速度达到恐怖的 2200T/s,整个生成过程在 1.5 秒内完成
来看看实际效果,这里我录了一个视频
{{< video "https://cdn.taurusxin.com/hugo/2025/11/10/cerebras-gptoss.mov" >}}
按下发送按钮后的一瞬间,整个代码都生成完了,一气呵成,。如果把它用在代码编辑器辅助编程,不敢想有多爽。
总结
这个平台目前知道的人并不多,价格表在 https://www.cerebras.ai/pricing
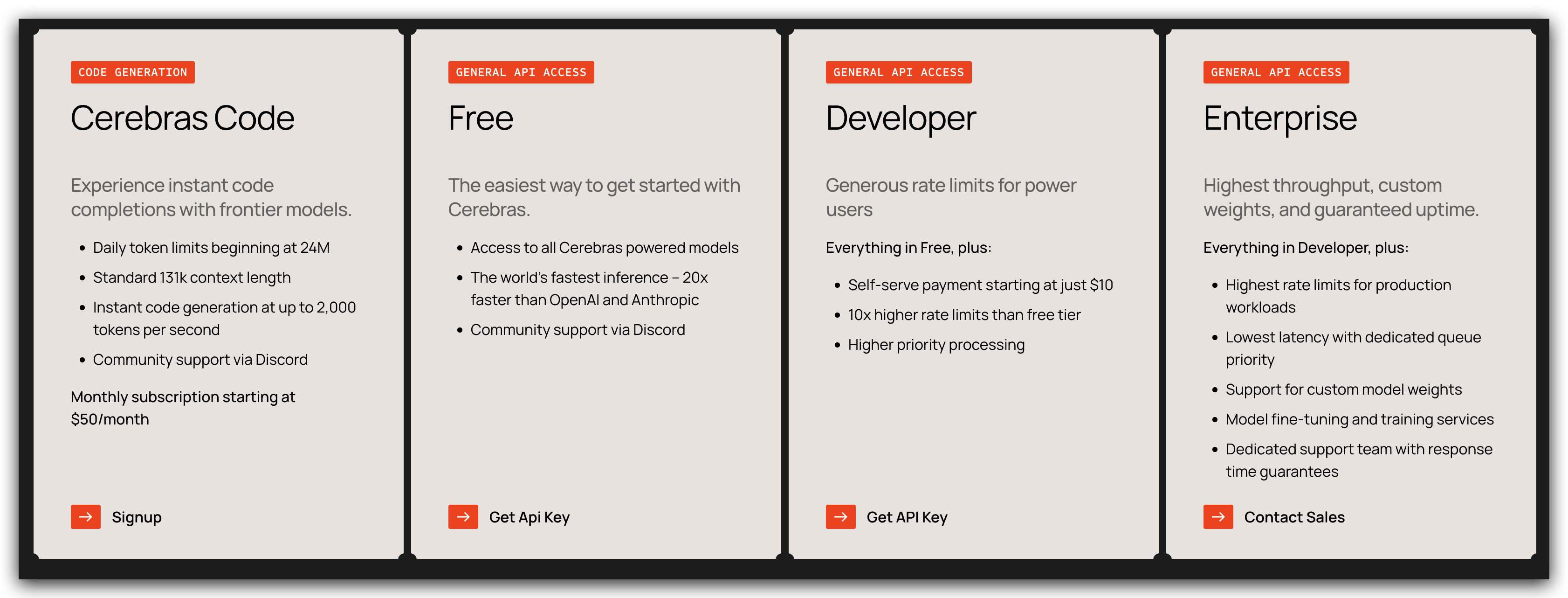
目前还推出了官方的 Code 服务 Cerebras Code,每天可用 2400 万 Token,最高 131k 的上下文支持,价格相较于其他代码生成服务比较贵,$50 每月,不过对于这么快的生成速度,也能接受。
至于免费版,我没有在文档中找到免费额度是每天或者每月多少,有找到的小伙伴可以说一下,免费版和付费版的输出速度是一样的,这点好评。